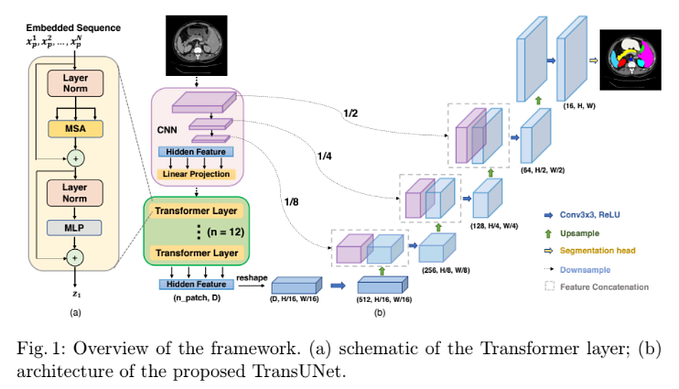
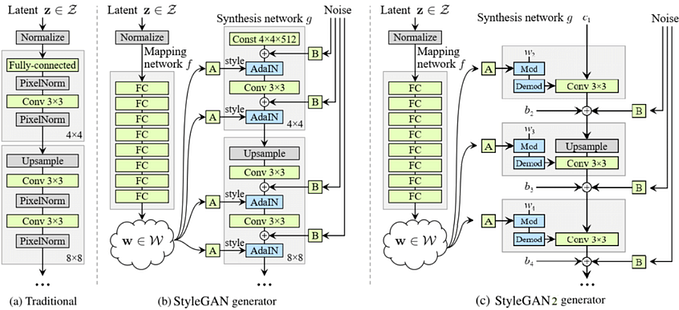
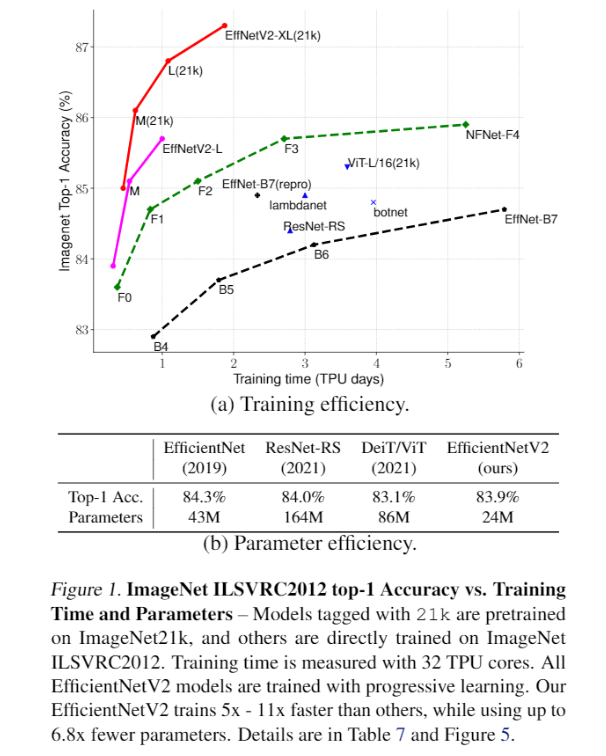
Introduction
- MoCo 的第二版,結合了 SimCLR,達到更好的效果。
- 下圖(a)的 end-to-end 為 SimCLR 的訓練方式,透過很大的 batch size 得到很多相同 batch 的 negative samples,並不會在下次訓練時用到,而(b)為 MoCo 的訓練方式,會把 negative samples 儲存到 queue,可於之後訓練時參考到。

Method
- 同樣是 InfoNCE loss,q 是 query (當前的影像),k_+ 是 positive sample,k_- 是 negative sample,要讓 q 和 k_+ 越像且和 k_- 越不像。

SimCLR 透過以下方式強化 end-to-end 的訓練方式,並透過各種實驗證明其有效性。
- 很大的 batch size 得到更多的 negative samples
- 利用額外的 MLP head 去 minimize loss
- 用更強的 data augmentation
而在 MoCo 的框架中可以透過 queue 的方式得到很大的 negative samples,另外也可以無痛升級成類似 SimCLR 的方式,新增 MLP head 和運用其他 data augmentation 的技巧,因此將其結合在一起並提出 MoCov2。
stantiated. Next westudy these improvements in MoCo.
- 實做上是把 MoCo 原本 encoder (f_c) 的 head 換成 SimCLR 提出的 2-layer MLP head (hidden layer 2048-d, withReLU)
- τ 即使用原本 default 的 0.07,加上 MLP head 也會有比較好的結果,但實驗結果來說加上 MLP 的 τ 在 0.2 可以有更好的結果。

- 這邊有做一些 ablation study,即使只有新增其他 augmentation (blur and stronger color distortion) 也可以提升 performance。

- 與 v1 和 SimCLR 的比較,MoCo v1 和 v2 就是差在有沒有額外的 MLP、新增其他 augmentation 和 Cosine learning rate。

- batch size 會提高記憶體用量,但除此之外因為 end-to-end 的方法需要 back-propagate 兩個 encoder,因此相對 MoCo 來說也會比較耗記憶體資源。