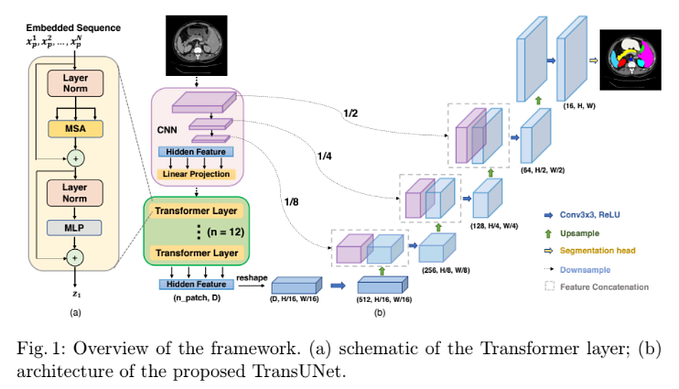
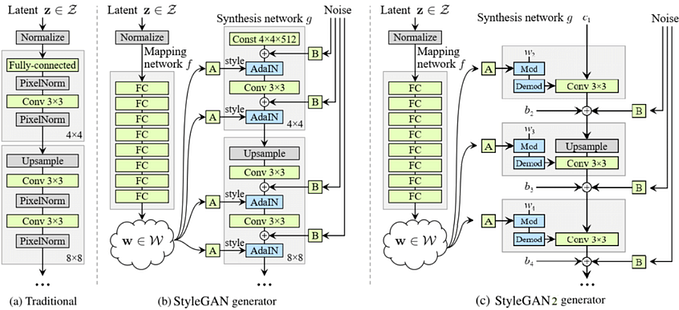
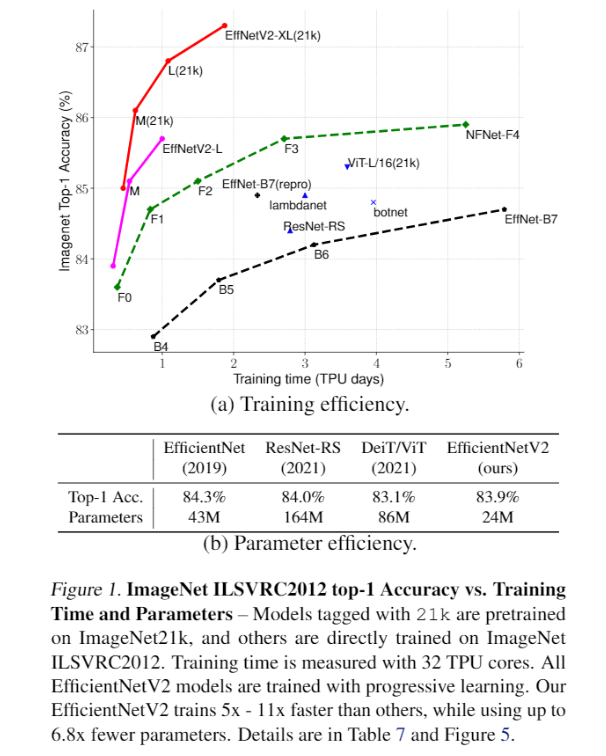
Introduction

- 本篇提出 Momentum Contrast (MoCo) 的方式建造很大的 dictionaries,透過 queue 的方式進行儲存 sample,把當前 batch 的資料 enqueue,最舊的資料 dequeue,且對資料進行 contrastive learning。
Method
- 假設當前的資料為 q(query),會有對應到一個 positive example (k_+),和其他的 negative example (k_i),loss 就會如下,q 要和 k_+ 越近越好、和 k_i 越遠越好,τ 是 temperature hyper-parameter 實驗設定為 0.07。

- 而 key 的 encoder 是透過如下方式進行更新,跟 BYOL 的做法相同,為一種 moving-averaged encoder,實做上 m 為 0.999,效果比 m=0.9 還好。

- pseudocode 如下,input 產生 positive sample,再從 queue 取 negative sample,之後做 enqueue 和 dequeue。

- 此外為了解決 intra-batch communication 的問題也採用了 Shuffling BN 的方式將 BN 套用在不同 GPU 上。
Experiment
- linear evaluation 的結果,論文裡面還有許多 transfer 到其他 dataset 的成果,有興趣可以去看論文。