前言
此篇重點就如下圖一所示,在一個 overparameterized 的 fixed, randomly weighted network 裡面其實可以找到一個 subnetwork 且 performance 差不多,且不需經過調參數或 normalize 之類的操作。

假設 τ 和 N 的架構相同,且 N 是透過任何一種 standard scaling of a normal distribution 進行 initialize 的 (例如: xavier, kaiming),就會存在一個 τ 可以達到和 N 相同 performance,且不經過訓練。
方法
透過計算 score 的方式而不是更新 weight 的方式去計算 edge-popup (作者提出的算法),如下圖,在 forward 的時候對每個 layer 選 top-k% scores 的,backward 的時候會更新他的 scores,更新的方式和 gradient 一樣的概念,哪邊的參數需要被調整,那他的 scores 就應該越大,因為就表示 network 一直希望這邊的值被 align,而不斷更新後就有可能在 forward 的時候被選到。

最開始先透過 kaiming normal initialization 初始化值

I_v 表示下一層的 input,w 就是 weight,Z_u 表示上一層的 output,h(s)表示挑選 top-k% 的 node。

至於 scores 的部分則透過以下公式 update,L 是 loss、α 是 learning rate。

當更新到一定程度之後 top-k% 的 score 會換其他 node 取代掉,因此這個mini-batch 的 loss 會突然降低。
實驗
分別使用相同 standard deviation 的 Kaiming Normal 和 Sgn Kaiming Constant 進行比較,這部分的設定論文講得滿細節的,有興趣可以去看看。
CIFAR-10
- 在 Cifar-10 上用了下面這幾種 VGG like 的 network 做實驗。

- 選擇不同比例的 k 的比較,大約50%最好,0% 的話等於沒有 weight,而 100% 的話就表示值都是 random 的。

- 以及比較不同 neurons 數量的結果,也就是增減其 channel 的數量。

- 跟 baseline model 的比較,但 baseline model 使用的是 xavier normal。

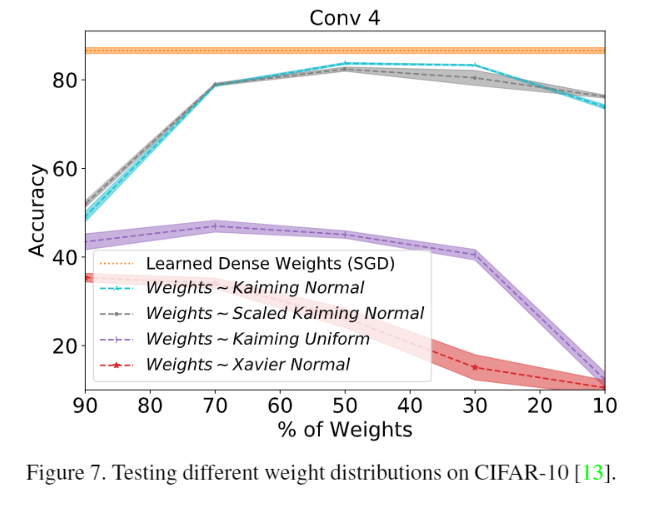
- 這篇也有針對不同的 init 方式進行比較,用其他方式還滿慘的。
ImageNet
- 跟上面差不多的比較方式,看圖就好

- 一樣有針對 k% 做比較

Reference
[arxiv]
