Vector-quantized Image Modeling with Improved VQGAN (ICLR2022 Under Review)
Introduction
此篇 ViT-VQGAN 為 VQ-GAN 的改良版本,沒看過的人可以看 The AI Epiphany 介紹的 VQ-GAN 和 VQ-VAE,這種類型的方法主要是要得到一個好的 quantizer,而 VQ-VAE 是透過 CNN-based 的 auto-encoder 把 latent space 變成類似像 dictionary 的 codebook (discrete learnable variables),VQ-GAN 則是透過 Perceptual loss 替換原本的 MSE loss 在加上 Adversarial loss 改良 VQ-VAE,而此篇則透過以下方式提高 VQGAN 的 efficiency 和 reconstruction quality,並用 end-to-end 的方式在 image-only 的資料進行訓練,使用的 loss 為 logit-laplace loss, L2 loss, adversarial loss and perceptual loss.
- Propose Vector-quantized Image Modeling (VIM) and apply it to both image generation and image understanding tasks.
- ViT-VQGAN yields better computational efficiency on accelerators, and produces higher quality reconstructions.

Method

Stage 1:
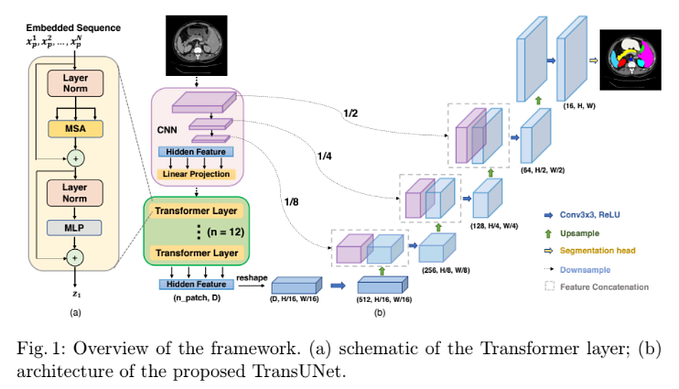
VQGAN WITH VISION TRANSFORMERS
- input 為 256 x 256,ViT-VQGAN 會用 8 x 8 non-overlapping patches 將其 encode 成 32 x 32 (1024 tokens) 的 8192 個 Codebook,在 Encoder/Decoder 的 Transformer output blocks 都有加 2 個 Feed-forward network 且在兩者中間加入 tanh activation,作者發現這樣的作法可以提高 quality。
CODEBOOK LEARNING
VQVAE 因為 Codebook 的 Initialization 不好導致使用率很低,VQGAN 是透過 top-k 和 top-p 的方式 Sampling,而此篇透過以下兩種方法改良。
- 降低 Codebook 的 Dimension
- Initial codebook from normal distribution 之後計算與 Latent vector 的 L2 normalization,提高兩者的 Cosine similarity

Codebook 的 Loss 如下和原本一樣,β = 0.25

VIT-VQGAN TRAINING LOSSES
Logit-laplace loss, L2 loss, perceptual loss based on VGG.
GAN loss with architecture of StyleGAN discriminator.

Stage 2:
For unconditional image synthesis or unsupervised learning, we pretrain a decoder-only Transformer model to predict the next token.
For class-conditioned image synthesis, a class-id token is prepended before the image tokens.
Transformer decoder 用來做 autoregressive 的預測,θ is learnable weights.

訓練的目標為 Minimize the negative log-likelihood.

用 Pretrained transformer 進行以下兩個步驟。
IMAGE SYNTHESIS
- 輸入為長度 1024 的 flattened image tokens,透過在 image tokens 前面加上 class-id token 將 unconditional generation 轉換成 class-conditioned generation。
UNSUPERVISED LEARNING
- 把 Image token 丟近來之後會得到一串 1024 的 Token features,然後把某些 Layer (l) 的 Output feature 拿出來做平均然後過 Softmax,讓這些 Feature 變成 Class logits,只拿中間一些 Layer 的 Output 效果比較好。
Experiment
Model 名稱後面如果是 SL 如 ViT-VQGAN-SL 表示 Encode 是用 Small size 而 Decode 是用 Large size,平常 Stage 2 只需要 ViT-VQGAN 的 forward propagation。
In inference/decoding for image synthesis, the decoder of ViT-VQGAN is still required to decode images from codes predicted during Stage 2

這邊有不同大小、架構和、Codebook dimension 的比較。

Default model size 是用 ViT-VQGAN-SS + VIM-Large。

在 ImageNet 的影像合成的結果和圖片。


做 Linear-probe 的比較,由於 Perceptual loss 是 based on supervised 訓練的 VGG 去進行計算的,所以這邊的 Model 並沒有使用 Perceptual loss。