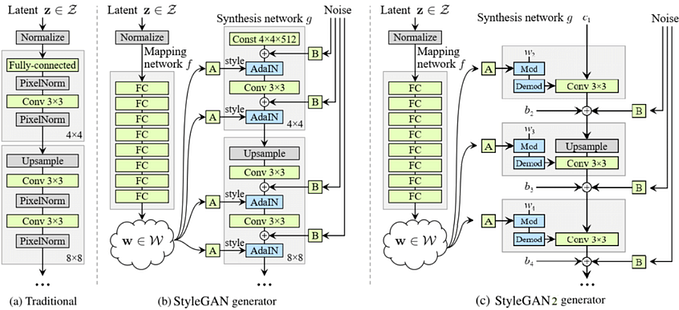
Method
- 此篇基於 ViT 及 UNet 做醫學影像的語意分割,ViT 的部分和原始 ViT 論文作法一模一樣,且有嘗試將 ViT 的 output 使用單純的 bilinearly upsample 輸出 N 個 channel(class) 的 segmentation,但因為 ViT 的 H/P*W/P 通常比原始影像的 H*W 小很多,所以效果不會太好,因此作者提出 hybrid 的 CNN-Transformer 來補足 low-level details,利用 CNN 取出 feature map 然後當作 ViT 的 input,架構上也和 UNet 一樣使用了 skip-connection,並透過網路的方式做 upsample。

Experiment
Synapse multi-organ segmentation Dataset
- 上半部比較 SOTA 的 model,下半部做 ablation study,None 的 decoder 表示使用一般的 bilinearly upsample,hausdorff distance 是指兩個集合若是要彼此包含的話所需要的最短距離。

ACDC dataset

Number of skip-connections

Input resolution

Sequence length and patch size

Model scaling

- 基本上這篇就是把原始 ViT 加上 UNet 架構而已,並沒有太多的改變和實驗,但根據其他論文和此篇論文可以看出在 ViT 之前加上 convolution 的效果都還不錯。