TransGAN: Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up
Introduction

- 此篇提出了不使用 convolution 而單純使用 Transformer 的 GAN 架構 TransGAN,其在訓練上有很多技巧,也因此才能夠達到 SOTA 的程度,以新架構來說算是很好的成果了,雖然目前來說解析度還很低。
- GAN 早在一開始也是透過 FCN 的方式,後來才變成 CNN-Based,而由這篇開始將 GAN 的架構帶向 Transformer。
Method

Memory-friendly Generator
- 由於 patch 數量的增加會令記憶體和計算量指數成長,因此作者透過 multiple stages upscale 的方式,如上圖2左,減少 patch 數量的同時加大長寬並在 64x64 之後同時減少 Channel,直到達到 target resolution。
- 從 Noise 經過 MLP 之後加上 position encoding 然後做 ViT, Upscale 的部分會先將 1D 的 patch sequence 變成 H_i*W_i*C 之後透過 pixelshuffle 做 bicubic upscaling 把解析度的長寬提高兩倍,如下圖方式,最後再透過 linear model 輸出 H*W*3 的 RGB 影像。

Multi-scale Discriminator
- patch splitting 是很關鍵的一部份,如果 patch 很大就會容易喪失一些細節紋理的部分,但是 patch 小又很耗記憶體資源,跟 CNN 的概念很像,所以作者提出 multi-scale discriminator 如上圖2右,將不同 patch 的同一張圖片分別經過 linear model 後丟到不同 layers 進行 concate。
- Average Pooling 的地方和 Upscale 類似,會先把 1D-sentence 轉成 2D feature map 然後再 downsample,在最後一個 block 的最前面會加上 [cls] token,讓 classification head 輸出 real/fake prediction.
Grid Self-Attention: A Scalable Variant of Self-Attention for Image Generation

- grid self-attention 就是將 resolution 大於 32x32 的 feature 限縮 self-attention 的 receptive field 到16x16 的 non-overlapped grids,而作者也針對 non-overlapped grids 可能造成 boundary artifact 進行解釋,他說在訓練的前期確實有這問題,但是因為其 discriminator 使用 multi-scale 的架構且有較大的 receptive field,這部分就和一般 ViT 的任務不太一樣,像是物件偵測等沒有 discriminator 輔助的任務目前看下來還是需要有 overlapped 會有比較好的效果。
Exploring the Training Recipe
Data Augmentation
- 因為 Transformer 相較於 CNN 是比較 flexible 的架構,因此需要比較多的資料進行訓練,且透過 augmentation 帶來的成效會比 CNN 明顯很多。
Relative Position Encoding
- 將原本 attention 的 position encoding 加在 attention layer 裡面變成,可以學到比較好的 relationship。



Modified Normalization
- 在 LN 之前先對每個 token 做 normalization,C 是 embedded dimension,用以讓 model 更穩定。

Experiment
Datasets
- CIFAR-10、STL-10、CelebA、CelebA-HQ、LSUN Church
Implementation
- 依照 WGAN 的設定並採用 WGAN-GP loss,採用 DiffAug[68] 的方式進行 Augmentation,Metrics 使用 Inception Score(IS)、Frechet Inception Distance(FID),用 16 個 V100 進行訓練。
Comparison with State-of-the-art GANs
CIFAR-10、STL-10、CelebA
- STL 比 CIFAR 的資料數量大兩倍,因此效果又會相較 CNN-based 的方式還好,成果如下圖。


Scaling Up to Higher-Resolution
- 因為有 Multi-scale discriminatior 所以影像會有比較豐富的 textures,在細節上也會有比較好的結果。
Data Augmentation is Crucial for TransGAN
- 可以看到在資料集不夠大時 Augmentation 對 Transformer 的影響很大。
we conduct {Translation, Cutout, Color} augmentation for TransGAN with probability p, while p is empirically set to be {1:0, 0:3, 1:0}
We also evaluate the effectiveness of stronger augmentation on high-resolution generative tasks (E.g. 256 256), including random-cropping, random hue adjustment, and image filtering. We show that it can further improve the FID score on CelebA-HQ from 10.28 to 9.60. Moreover, we find image filtering helps remove the boundary artifacts in a very early stage of training process, while it takes longer training iterations to remove it in the original setting.

Ablation Study
- baseline method (A) 是指使用 memory-friendly 和普通的 discriminator,下面的數值是 FID。

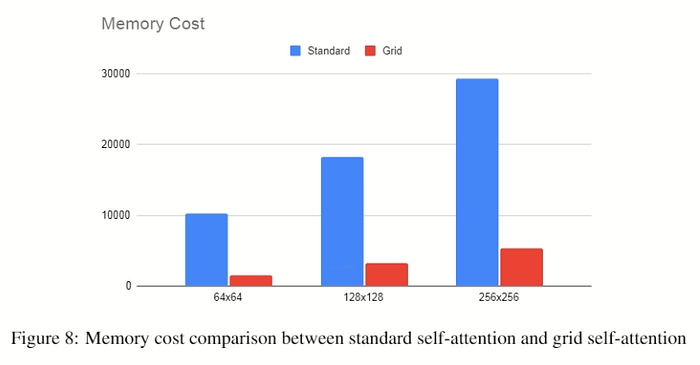
- 下圖為是否使用 grid self-attention 的記憶體使用量,但沒提到 Y 軸的單位是什麼。
Understanding Transformer-based Generative Model
- 找了一個也是 multi-scale representation 的 model 進行訓練過程和 latent space interpolation 的比較,可以發現 CNN-based 的 GAN 在早期訓練的比較好,且有 smooth interpolation。

Conclusions
雖然在記憶體使用量很可怕但未來往高解析度的方向是個必然的趨勢,可以期待之後的論文如何去實做,整理一下此篇的三個貢獻如下:
- Build the first GAN using purely memory-friendly generator and a multi-scale discriminator transformers and no convolution. And is further equipped with a new grid self-attention mechanism.
- We study a number of techniques to train TransGAN better, including leveraging data augmentation, modifying layer normalization, and adopting relative position encoding, for both generator and discriminator.
- TransGAN achieves highly competitive performance compared to current state-of-the-art GANs.
