Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
Introduction
- 此篇為 ViT 的延伸閱讀,原始 ViT 的 patch 使用固定大小且在圖像中並沒有重疊的部分,導致會少考慮到一些空間上的資訊,另外作者也發現原始 ViT 有「redundant attention」的現象,以上兩個問題導致輸出的 feature map 會有如下圖的問題,分別是缺少 edge、line 的特徵和有些全白或全黑的輸出。

- 因此作者提出了 Tokens-to-Token module 解決鄰近 patch 的 local structure 資訊量的問題,並借鑒 CNN 提出了 Deep-narrow 的 Transformer 提升速度降低參數量。
Method
此篇提出兩個架構,第一個是 Tokens-to-Token module(T2T module),用來提取 local structure 的資訊以及減少 token 的長度,第二個是 T2T-ViT backbone,把 T2T 的 output 做 attention,並使用 deep-narrow 的架構。

Tokens-to-Token: Progressive Tokenization
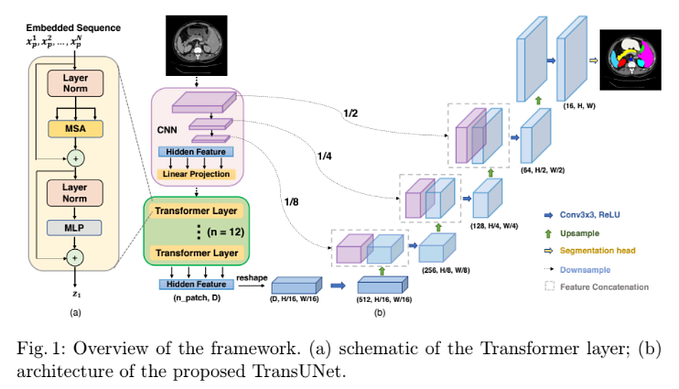
- T2T Transformer 是指任意一種 ViT 的架構(作者採用 Performer),概念很單純就是把 Transformer 的 output reshape 成像影像那樣然後做類似 convolution 的方式來減少 token 數量,然後加深深度,整體流程如 Figure 4,先soft split 之後再做兩次 T2T,input size 為 224x224,output size 為 14x14,然後丟到 T2T-ViT Backbone。

T2T-ViT Backbone
- 主要解決 Figure 2 的「redundant attention」,並對 Transformer 減少參數加深層數,原始的 ViT-B/16 有 12 個 Transformer layer,768 hidden dimensions,T2T-ViT-14 則用 14 個 Transformer layer,384 hidden dimension 實現 Deep-narrow 的架構,如下圖右邊,最後在經過 MLP predict。

Experiment
- T2T-ViT-XX 後面的 XX 表示 Transformer 的層數和對應比例的 hidden dimensions,為了實驗公平比較其他 model 故意用成參數量差不多進行比較。

Train from scratch on ImageNet
- 384 的是指 input image resolution,[38] 是用 Distillation 的 model。

- 為了實驗公平比較 CNN based 的 model 故意用成參數量差不多進行比較,這邊比較的是 ResNet。

- 這邊比較 ModbileNet。

Transfer learning on CIFAR10/100

From CNN to ViT
- 透過不同 CNN 的架構強化 ViT 做實驗,可以看到 ViT-DN(Deep-narrow)效果好又減少參數量,因此有套用到 T2T-ViT 的架構中,表格提到的相關架構可參考此文章或論文。

Ablation Study
- wo T2T 表示沒有 T2T module,_t 的是用一般 Transformer,_c 是把 T2T 改成 3 個 convolution layers,d768-4 是指 hidden dimension 768、4 layers。

Reference
[arxiv]