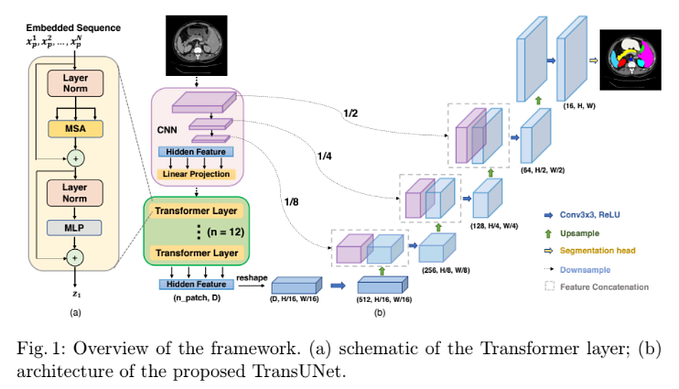
Involution: Inverting the Inherence of Convolution for Visual Recognition (CVPR2021)
Introduction
- 探討一般的 convolution 在電腦視覺領域的特色,並提出新的卷積架構 「Involution」,另外也近一步套用 self-attention 的機制到 Involution。
convolution 有兩大特色分別是 spatial-agnostic 和 channel-specific
- 「spatial-agnostic」表示 kernel 在空間上有一致性,可以針對不同圖片的位置找到相同的 patterns,同時針對空間進行壓縮,透過多層的方式加大 respective field 和 patterns 的多樣性,缺點就是難以捕捉 Long-range 的空間關係。
- 「channel-specific」表示在 channel 進行 encode,整合 channel 上的多樣性,在一般 CNN 的架構裡面如何定義 channel 的數量也是門學問,即使在現在非常成功的 CNN backbone 裡面也存在許多 inter-channel redundancy。
Involution (Invert Convolution)
- 為了解決上面提到的問題,此篇提出的 Involution 採用和一般 convolution 相反的方式,也就是 spatial-specific 和 channel-agnostic,在 channel 上共享權重。
Concretely speaking, involution kernels are distinct in the spatial ex-tent but shared across channels
- 因此在空間上有更好的匯整能力可以克服 Long-range 的問題,且可針對不同位置透過產生 kernel 的方式給予不同權重。
(i) involution could summarize the context in a wider spatial arrangement, thus overcome the difficulty of modeling long-range interactions well;
(ii) involution could adaptively allocate the weights over different positions, so as to prioritize the most informative visual elements in the spatial domain.
Method
複習一下原本的 Convolution
- 這是一般 convolution 的公式,對每個 output vector(Y) 來說就是把 input vector(X) 乘上對應位置的 kernel(F),而這邊的 Δ 表示 kernel 大小,可以注意到是在空間上的變化。


- 而 depthwise 的作法部分 kernel 就不會考量到整個深度,只會在固定的 channel 下進行,以保持結構,因此公式就會如下。

Design of Involution

- 下面是 Involution 的公式,感覺上和 depthwise 的差不多,但是可以看到這邊的Y 和 H 下標都是 (i, j),也就是此操作的輸出是透過同一個長寬座標位置的深度權重進行計算,因此其權重是在 channel 上共享,而 depthwise 則是在空間上共享。

- 為了方便解釋也可以用以下方式標示,φ 為 Kernel generation function,詳細運作方式可以參考下面 Pseudo code,也是此篇論文的重點,詳情也可以參考他的 github。


- Psudo code 有兩個重點,一個是 Kernel generation function(φ) 也就是下面的變數 「kernel」產生如上圖 1 的 H,另一個是 Unfold 也就是下面的變數 「x_unfolded」產生如上圖 1 的 K*K*C 空間資訊,兩者相乘後讓產生的 「kernel」 可以參考空間上的資訊「x_unfolded」,裡面比較特別的變數 r 是 Reduction ratio,表示在 channel 上壓縮的程度,最後面有實驗比較。
- φ(kernel) 實際上就是 Pool(o)->FC(reduce)->BN->ReLU->FC(span)->Reshape。
- x_unfolded 則是 Unfold(x) -> Reshape。


- 假設我們有個 32 channel 的 input,c = 32,k = 3,實驗設定的為 r = 4, G = c//16 = 2,則 input 經過 φ 之後的大小為 (B, G, K*K, H, W) = (B, 2, 1, 9, H, W)。
- 另外 Unfold 的部分則為 (B, G, C//G, K*K, H, W) = (B, 2, 16, 9, H, W)。
- 兩者相乘之後會得到與 Unfold 一樣大小的 vector (B, 2, 16, 9, H, W),之後 sum(dim=3) 表示把 kernel 乘上的值相加起來得到 out (B, 2, 16, 1, H, W),最後透過 reshape 的方式還原回原本圖像的空間,(B, C, H, W) = (B, 32, H, W)。
Attention Mechanism
- 下面為 attention 的公式,作者認為 H 可以當成 attention 的 QK。

- 將 Involution 原本輸入的位置在加上空間上的鄰近向量也可以達到類似的效果。

- 在 Involution 的架構中所生成的 kernel 本身就是有按照順序的,因此 relative positional 的資訊也會含在其中。
Experiment
- 將 ResNet 的 convolution 改為 involution 並訓練在 ImageNet 的比較表格,參數量和精準度上都有不錯的表現。

- performance 和 parameter 的 trade-off,視覺化上面的表格。


- 此外也有在物件偵測和 segmentation 這些熱門的應用上做實驗比較,不管是在參數量上還是 performance 的部分,效果都比一般 convolution 好。

- 而且在大物件上做 Segmentation 效果特好。

Ablation Study
- 提高 kernel size 只增加了一些運算量卻可以提升精確度,但在 7x7 之後就不明顯了,可能和影像的解析度有關
- group channel 表示 share weight 的 kernel 大小,可以看到完全不共享和共享 16 個其實準確度才差 0.2,也可以呼應前面提到的 inter-channel redundancy。
- Function Form 這邊是比較 Kernel generation function,r = 1 時表示不做壓縮,反之則是壓縮的倍數。