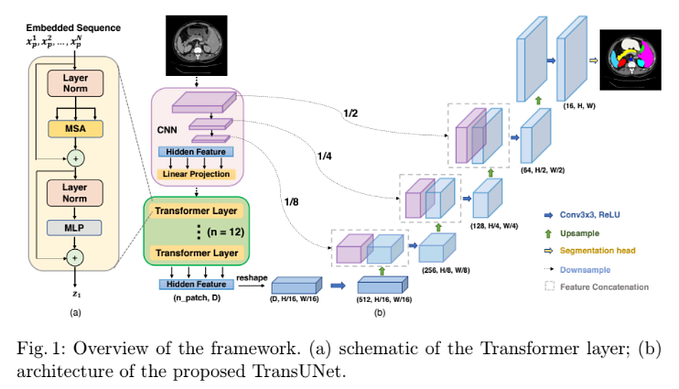
針對之前的 model 提出了幾個問題,並進行改良
(a) 單純示意 gaze estimation 這個領域的任務,預測出人在圖像中看的位置
(b) 幾乎都是仰賴 2D 影像而沒有參考到深度資訊,需要有效地透過 3D 資訊處理。
(c) 透過 2D 影像資訊找特定方向的 salient objects,容易因為缺少深度資訊無法正確地預測,因此需要和此人與周圍環境相對的深度資訊。
(d) 用頭部資訊去預測看的方向也會因為頭和眼睛的方向不一致導致錯誤,因此需要學習眼睛和頭之間的關係。
因此提出 three-stage 的架構
- coarse-to-fine 的方式預測頭部在三維空間中看的方向,以及預測出影像上的深度。
- 提出 Dual Attention Module (DAM),透過頭部在三維空間中看的方向產生不同的 view 然後和深度的資訊做 attention。
- 最後將輸出的 attention map 和原始圖像做 concate 丟入 backbone,再透過 BC 輸出 in/out,以及 decoder 輸出 heatmap。
貢獻如下:
- 提出 DAM,透過深度資訊和 FOV 做 attention。
- coarse-to-fine 的方式預測 3D gaze orientation。
- SOTA on GazeFollow and VideoAttentionTarget benchmark。
Method

3D Gaze Estimation
- 將頭以及左右眼的影像分別輸入,透過 MLP 預測頭部在三維空間的方向 g,如果沒偵測到眼睛就單純使用 head 預測,有偵測到就會透過眼睛去得到 fine-grained 的資訊,而 g_z 的部分如果是正的表示是往後看,反之則往前看。
- 頭部的位置有 ground truth 資料,但是眼睛的部分沒有,作者有透過一些現成的 model 去取得眼睛的資訊,但考慮到側臉或背對相機可能會有遮擋的問題,因此透過 Gaze360 抓模型輸出 60 度以上則不參考眼睛的資訊,也有透過 Face alignment 計算兩個眼睛的距離過近也不納入參考,若是沒找到眼睛的資訊則改以全黑的圖像代替。
Dual Attention Module
- FOV generator 透過平面資訊 (g_x, g_y) 生成出 FOV,Depth rebasing 則是透過 Depth estimation model 輸出的原始影像深度圖並基於頭部的深度資訊做 rebase 然後和深度資訊 (g_z) 做 rule base 的篩選,再將輸出的相對深度圖和 FOV 做 attention。
- FOV 影像的生成或透過計算 pixel 位置 (i, j) 與頭部位置 (h) 的差和預測平面角度 (g_x, g_y) 的內積做 arccos,值越小表示夾角越小。

- 因此可以透過計算 1 減掉每個 pixel 算出來的值並給予適當的權重產生出 M_f (上面的錐狀 FOV 圖),實驗上 α 設為 6 表示 60 度角。

- 而 Depth rebasing 的部分是透過計算頭部的深度資訊平均,將其值當成 threshold,由於深度圖的值越大表示越近,所以透過以下公式將原本的深度圖減掉頭部的平均進行 rebase,Ω 表示頭部 bbox 的 pixel 範圍,因此 F_d 大於 0 的地方則表示此物件在此人的前面。

- 因此主要將 F_d 分為前/中/背景,mid 表示其值離 0 很近,τ 設定為 16。

- 再將切分下來的前/中/背景根據 g_z 產生出來的值做 rule base 的篩選,因為 g_z 小於 0 表示往前看所以得到的會是前景,反之則是背景,因此可以判斷說預測的 g_z 應該會看到深度圖的哪些部分,δ 設定為 0.3。

- 最後將 M_f 和 M_d 相乘計算 element-wise product。
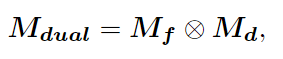
Gaze Target Detection
- 將 M_dual 和原始影像做 concate 之後丟到 backbone,訓練 Binary classifier 和 Heatmap Regression Head。
- Binary classifier 是兩層 convolution + 一層 linear model,輸出 in/out。
- Heatmap Regression Head 是兩層 convolution + 三層 deconvolution,輸出 logits map,heatmap 值最大的部分就是 gaze point。
Loss
以下皆為 supervised 的 loss,有 ground truth 資料。
- L_Cls 是 Binary classifier 的 BCE loss,判斷 in/out。
- L_Reg 是 Heatmap Regression Head 的 Mean squared error loss。
- L_Ang 是 planar angular loss,計算 (g_x, g_y) 偏差的角度,d 是 ground truth 的平面角度資訊。
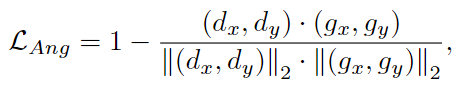
- 整體的 loss 如下,

Experiment
- 先 pretrain 3D gaze estimator 在 Gaze360 dataset
- Binary Classification Head is trained on the GazeFollow
- finetune the full model on the VideoAttentionTarget dataset
- 下面是在 GazeFollow 和 VideoAttentionTarget 的 performance


Ablation study
- DAM-None: 直接用 Scene Image 當第三個 stage 的 input
- Depth-None: 把 Depth rebasing 的 output 改 uniformly-weighted map
- FOV-None: 把 FOV 的 attention map 改 uniformly-weighted map
- Eye-None: 只用頭預測 head pose
- Scene-None: 只用 DAM 的 ouptut 當第三個 stage 的 input
- L_Ang-None: 沒有 L_Ang loss

- 因為有輸出角度因此也可以比較 Gaze360 的 model。

- 因為有使用到別人的 model 輸出深度,因此這邊有比較幾個 model 訓練出來的結果。

- 輸出的示意圖如下,黃色是 ground truth。