Big Self-Supervised Models are Strong Semi-Supervised Learners (NeurIPS2020)
Introduction
此篇為 SimCLR 的第二版,兩者概念都相同,跟 NLP 任務一樣會先從 Self-Supervised 的方式得到 General 的 Pretrained presentation 之後再用少量的 Labeled data 做 Supervised fine-tuning,藉此完成 Semi-Supervised learning。
此外也可以透過 distillation 的方式再次利用 unlabeled 的資料,提升最後在 Fine-tuning 任務上的結果。
主要有以下三個步驟:
- 使用 ResNet 和 SimCLRv2 做 Unsupervised 的 pretraining
- 用部分 Labeled data 做 Supervised fine-tuning
- 運用 Unlabeled data 進行在特定任務使用 distillation

然後有幾個透過實驗得出來的結論:
- 用越大的網路 (deep and wide) 做 self-supervised pretraining 或 fine-tuning 會大幅增加準確度,且越少的 label 效果越明顯。

- 透過 distillation 的方式做 fine-tuning 可以讓模型適應指定的任務並減少模型大小(或是說減少多餘的參數),同時做第二次的 self-supervised。
- projection head 的深度也可以改善 representation quality,並提高從 projection head 的 middle layer 做 fine-tuning 的 performance。
Method

與 v1 不同的地方
- 用了更大的模型進行實驗 (ResNet-50 to ResNet-152 (3+SK))
- 使用更深的 projection head (2-layer to 3-layer)
- 使用移動平均 weight 的 memory network 並將其輸出當成 negative examples
Self-supervised pretraining with SimCLRv2
- 與 v1 一樣的架構對兩個不同 augmentation 的結果透過 ResNet encode 之後再接上 MLP projection head 計算如下的 contrastive loss。

Fine-tuning
- task-agnostically 到 task-specific 常見的作法,v1 pretrain 完之後是直接把 projection head 丟掉然後在 encode 完的地方 fine-tuning,v2 則是在 projection head 的 middle layer 進行 fine-tuning,就可以直接把他當成特定任務上的 head 來使用。
Self-training / knowledge distillation via unlabeled examples
- 使用 psudo label(P_T) 計算 cross entropy 達成 distillation,只訓練 student。

- 下面是 P 的式子,表示 output 的機率比重。

- 另外前面也可加上 label data 的 loss 進行計算,只是此篇論文並沒有使用

- 不管用一樣的架構或是更小的架構都可以增加精準度。
Experiment
Bigger Models Are More Label-Efficient
- 不同 size、label數量的比較表格,可以看到152(3x)和152(2x)參數量差了兩倍但沒有明顯提升,已經接近飽和了。

- 下圖驗證了不管哪種方式,越大的 model 越能從 label 中提取更好的資訊,實驗中還有用一些不同架構的 model,例如是否使用 selective kernel(SK),證實架構也會直接影響到這些效能。
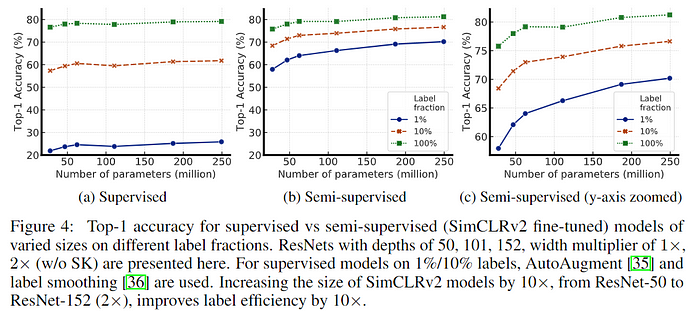
Bigger/Deeper Projection Heads Improve Representation Learning
- 比較深的 projection head 效果比較好(下圖a),而 fine-tuning 選用第一層的 projection head 效果比較好(下圖b)。

Distillation Using Unlabeled Data Improves Semi-Supervised Learning
- Distillation loss 在 Unlabel data 的影響很大。

- 不管是 Self-distillation 還是用用比較小的 student model 都可以提升準確率。

- 最後是跟其他方法比較的結果

